
i was curious how unlikely exactly this would be.
The randomUUID method generates a new version 4 UUID
which is, According to the linked documentation, a 128bit number, with some “significant bits” being changed (no idea what that’s about, lets just say it’s a 128bit number)
the chance of hitting a predfined number would be
1/(2^128) or 1/340282366920938463463374607431768211456
assuming your cpu does one comparison per Step at 4Ghz (4 billion per second) (idk how many steps it needs in reality, it doesn’t matter, more then one tho)
that would take roughly
2.696 x 10^21 years, which is
2 x 10^11 or 200000000000 times the age of the universe
(using the expected value of geometric distribution (1/p), so 1/(1/(2^ 128)) = 2^128 steps)
…so your saying theres a chance.
99.999999999999% chance the lava lamp inside your computer is broken.
I was able to reproduce this exactly.
An opportunity to share one of my favourite StackOverflow questions of all time!
It’s well worth reading through the answers and the comments, but here’s a little sampler platter:
This will run for a lot more than hours. Assuming it loops at 1 GHz (which it won’t - it will be a lot slower than that), it will run for 10790283070806014188970 years. Which is about 83 billion times longer than the age of the universe.
damn - so maybe serveral threads generating guids is a better idea?
4 threads on a quad core processor would make it run in 20 billion times the age of the universe - so yeah, that would help a lot.
Apparently the guy now works at the federal crime office (bka) in Germany now😂😂
His description is “we all have our segfaults”
figures
Perhaps run 20 billion threads and you will end it by the time the universe doubles its age.
What? I can’t set
/proc/sys/kernel/threads-maxto 20 billion‽
Gotta send a bug report to the Linux kernel.
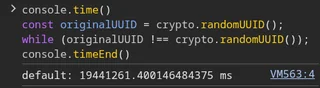
Only 5.4 hours before you hit a UUID collision. That’s insane
This is how we find out that crypto.randomUUID is not cryptographically secure
Aren’t UUIDs designed to prevent collisions, rather than be cryptographycally secure? Not that it’s doing a great job here :D
Edit: Nvm, that was guid.
GUID and UUID are two names of the same thing. One is Globally Unique and one is Universally Unique. I think they mean not cryptographically secure as in not truly random if it’s generating duplicates.
I was doing cybersecurity for a few years before I moved to gamedev, and I vaguely remember that at least the older versions of GUID were definitely not safe, and could be “easily” guessed.
I had to look it up, in case anyone’s interrested, and from a quick glance to the GUID RFC, it depends on the version used, but if I’m reading it right, 6 bits out of the 128 are used for version identification, and then based on the version it’s some kind of timestamp, either from UTC time or some kind of a name-space (I didn’t really read through the details), and then a clock sequence, which make it a lot more guessable. I wonder how different would the odds be for different versions of the UUID, but I’m too tired to actually understand the spec enough to be able to tell.
However, for GUID version 4, both the timestamp and clock sequence should instead be a randomly generated number, which would give you 122 bits of entropy. It of course depends on the implementation and what kind of random generator was used when generating it, but I’d say it may be good enough for some uses.
The spec also says that you specifically should not use it for auth tokens and the like, so there’s that.
just to be clear since you said both again in different sentences, GUID and UUID are two names for the same thing.
I think that spec predates uuid4, it only mentions the time based/node based variants. 122 bits of auth token should be plenty, right?
the sheer unlikeliness of guessing that large a number, the original post is fake or something else is going on.
Against a apecific one too. Usually you’d check for duplicates against all previous uuids
That would indeed be way (quadratically) more likely but we don’t count the number of attempts but measure run time, and since comparisons (even with optimizations like insertion sort) take time, the speed difference between the two methods will be “just” a few orders of magnitude.
As long as you don’t run out of memory, you can actually insert and lookup in O(1) time for a known space of values (that we have). Therefore we do get the quadratic speedup, that when dealing with bits of keysize or entropy means cutting it in half.
Checking to get a specific uuid takes 128bit, so 2128 draws of a uuid. Putting all previous uuids into a table we expect a collision in 64bit, so 264. We also need about that much storage to contain the table, so some tens of exabytes.
Either this is faked for the meme or something is very very wrong.
I’m leaning heavily towards faked for the meme.
If you actually were trying to get collisions, you’d save all previously generated ids and check all of them for a match with the newest one.
Not only would this increase the chance of a collision (not enough that it should matter, but still), but it would more closely approximate a real use case - if you use UUIDs you’re not just in trouble if two consecutive ids are identical, it’s usually a problem if any two ids are.
But the presented snippet is simpler and shorter and is close enough to what a naive test might look like, so it’s well suited to getting the joke across.The only way I could imagine this not being fake is if it was achieved in a noncompliant Js implementation. Which seems highly unlikely given the screenshot looks like the Chrome console.
This is probably due to sub standard random numbers. UUIDs are unique. If you manage to duplicate one your doing it badly.
If it was random once, why shouldn’t it be on the 163rd repetition?
This is the fucker who put us on the worst timeline! Get their ass!
Let’s hang this little shit!
If this is reproducible without chicanery, I’m terrified
Without chicanery? Yes
Without luck? No
I think this is beyond luck. This is astronomical. It’s orders of magnitude beyond what is lucky for our entire civilization to have produced in its entire existence
I’d put it down to a shit library or pseudorandomness before something happening that’s so lucky it functionally should never happen.
Agreed. Most likely a bad implementation.
For example, if the browser does time fuzzing, this could make the UUID less random.
Please tell this is fake. I want to be ignorant about this.
No problem. It’s fake. No need to look deeper.
is this cryptomining?
crypto - as in cryptography, not cryptocurrency - is just the library he’s using to generate the 128-bit random UUID. The snippet is interesting because he matched the original UUID in just over 5 hours. You’d expect to need more than 10^38 guesses to pick the same number again, which, even at 1 guess every microsecond, means something like 10^22 years.
I wanted to downvote you for failing to pick up on the sarcasm, but then you went and did all that math that I was too lazy to do and I ended up upvoting you instead. Damn you!
Sorry, I forgot to add the
/s.But thank you for the calculations, it’s actually interesting :) I was thinking about that myself, but didn’t bother to do the math.
I thought its reminiscent of cryptomining as it also consist of guessing an arbitrary number just for fun.
Internet sarcasm is hard, and lemmy has a very general audience :) I’m always happy when someone gives me an excuse to do the math I was already curious about - it’s often not worth it, for just my own curiosity, but even a sarcastic or disingenuous prompt reminds me that there’s other casually curious people out there.
I don’t understand
console.time()jots down the current time, if you do that twice and put stuff in the middle you get two times and the difference between them is how long that stuff took to doconsole.timeEnd()uses the last execution ofconsole.time()as the starting point to work out how long the stuff took to doconst originalUUID = crypto.randomUUID()generates a Universally Unique IDentifier, which can be thought of as a very large very random number, by use of a pseudorandom number generatorwhile(stuff)evaluates the stuff for truthiness (1 + 2 = 5 would be false, 50 < 200 would be true, ‘my username starts with the letter k’ would be true) it’s typically followed by a ‘block’ of code, that is lines beginning with{and ending with}, but we don’t see that here, which means we can readwhile(stuff)as “keep checking ifstuffis true in an endless loop, and only continue to the next line if one of the checks ends up beingfalse”the
stuffhere is creating another random UUID, and checking to see if it’s the same random number as the first one generated.functions like this are so incredibly random that chancing upon two executions creating the same number should be practically impossible. staggeringly impossible. If so this code should never complete, as that
whilecheck would be endless, never finding a matchthe image suggests that one such match was found in about 19 million milliseconds (a bit over 5 hours). this is probably faked, because the absurd unlikelihood of the same number being generated in so much as a single human lifetime, let alone a day, is laughable
the imagine is faked or something is terribly wrong with their pseudorandom number generator
But you can’t say that it’s fake or broken just because it’s unprobable, unless there’s supposed to be some additional safe guards to prevent the same random value from repeating within a certain distance from itself.
from a purely mathematical standpoint, yes
from a practical engineering standpoint, no, it’s impossible
I’m pedantic as they come, but pedantry has little use in an engineering discipline, software engineering included
like, if I take a cup of water and pour it into the Pacific Ocean strictly speaking I can say I “single-handed raised the water level of the ocean” and you’d be correct in the most unhelpful way
for the code in question if the PRNG is working as expected then for all meaningful purposes it can be considered impossible
edit oh also to fight pedantry with pedantry, technically even a check that would prevent duplicates might not prevent duplicates because you could argue there’s a non-zero chance a random cosmic ray flips just the right bit at just the right moment rendering even that pure chance. anything engineered (and not pure mathematical theory) has to draw the line of plausibility somewhere because we’re engineering inside of a chaotic reality. drawing the line to say that the image above is functionally impossible is just fine.
It just irked me that whenever something highly improbable happens it must be fake.
But I guess that’s just the proper way to view anything on social now-a-days.
We M-x butterflying now
Oh wow thank you
Insanely unlikely giant random number matches other insanely giant random number
The function first generated a random UUID. This is a long string of random characters, used in many software systems to uniquely fingerprint things, transactions for example. In theory, you can have millions of seperate systems, each generating UUIDs all the time without ever having to worry about a collision (a collision is one or more systems generating the same UUID, therefore it being not unique anymore)
The second line then runs UUID generation again, trying to generate an identical UUID to the one it already made. Tis is absurd because even a dmsupercomputer trying to generate identical UUIDs would take longer than the lifespan of the universe.
The console line shows that a matching UUID was apparently found after some amount of time, which shouldn’t be possible, implying some fuckery with the random number generator.
I wish I was a good enough coder to understand what’s going on, too. I bet it’s funny as hell.
They’re basically trying to find the time to create duplicate UUIDs. UUIDs are randomly generated and assumed to be so unique and actually random across… well, everything, that no one even checks if they’re actually unique. They suggested they found one in 5 hours. The only maybe possible way I could think of to do this legitimately is to use some ridiculously powerful computer and still get very lucky.
Ah! And this is why I don’t really care that much about long passwords or things of that nature. If the attack is brute force, it could still get lucky and guess it in 5 hours just like this UUID thing!
The chance to get lucky and pick a long, random password is still ridiculously small. The chance to pick admin123 is ridiculously large. You see the difference?
Length doesn’t matter if it’s randomly trying every possible combination. It could just as easily guess the longest possible password as the shortest.
Other methods of attack would be a good reason to make it long and nonsensical; not a random brute force attack.
With this logic you could say the chance to hit the lottery jackpot is the same as if the numbers are just 3 digits long. It’s not trying all the possible combinations all at once.
If the password was forced to be a specific length and could not be shorter or longer, it would be the same as that. But they’re not usually forced to be a specific length. They do have bounds, but that also makes it so there are fewer possible combinations to guess.
I know how I’m heating my office this winter












{kind=link}