

Siskind’s “chat vet local election candidates according to random pundits I like and also some other broad preferences” is both grossly misrepresenting the technology’s abilities as well as normalizing habits that would look obviously irresponsible in any other context, like voting by random online quiz as you describe.
Additionally, I would think most countries have various unofficial voter to party matching online services at this point, but they don’t have nearly the penetration or the cultural clout of the all knowing chatbot (voters skew old and have access to chatbots via social media, but good luck making them take an online test), and local online services are also much more sueable if a candidate thinks they are being misrepresented.


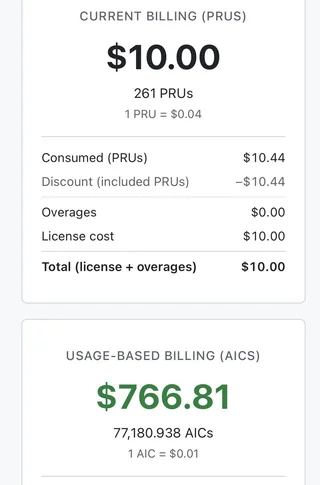
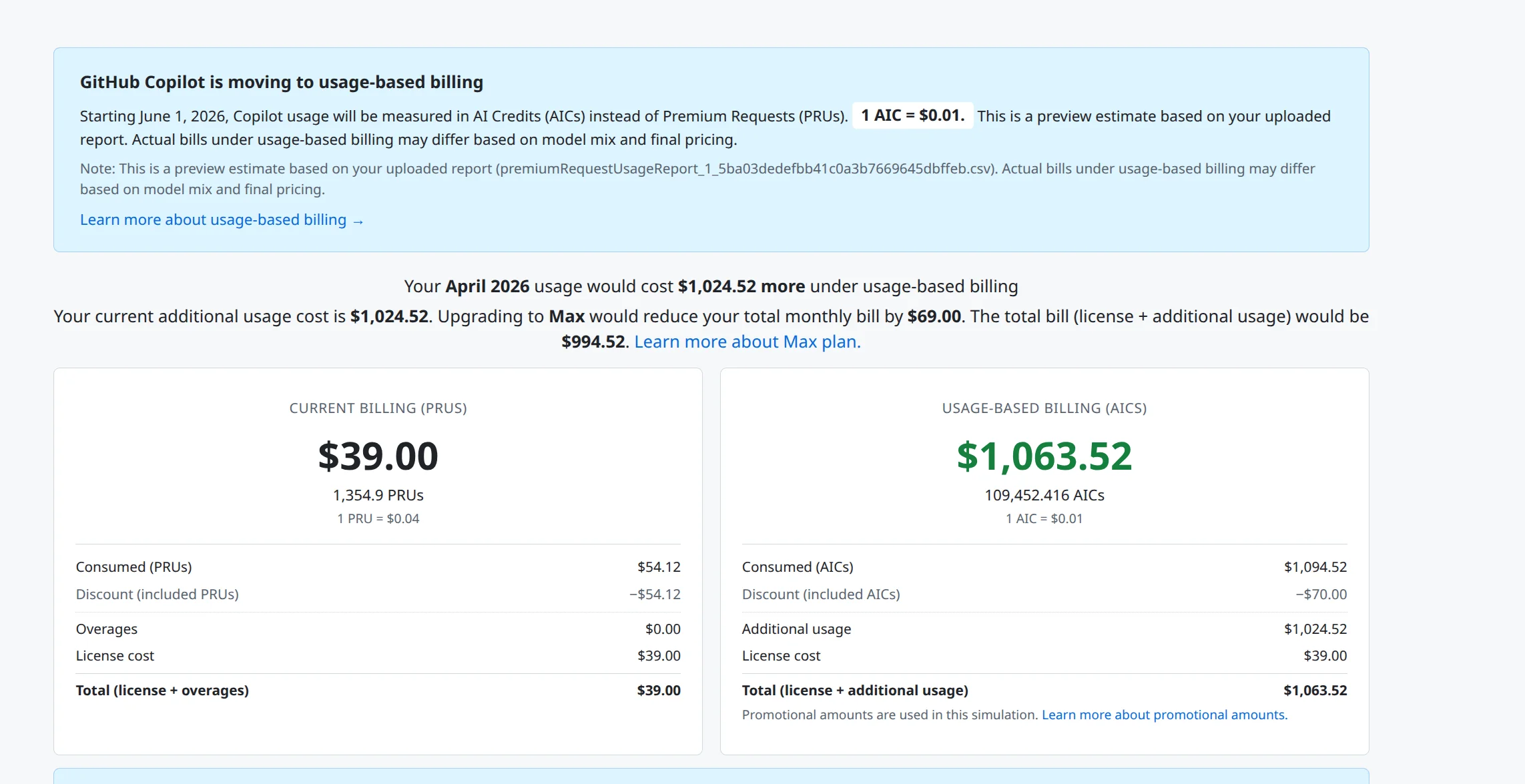







LessWrong, an online community that started out as a place to discuss Yudkowski’s writings, who among other things is the If You Build It Everyone Dies guy.
LessWrong also directly gave us Effective Altruism and the Zizians.