In these specific examples it looks like the author found and was exploiting a singular weakness:
Ask a reasonable question
Insert a qualifier that changes the meaning of the question.
The AI will answer as if the qualifier was not inserted.
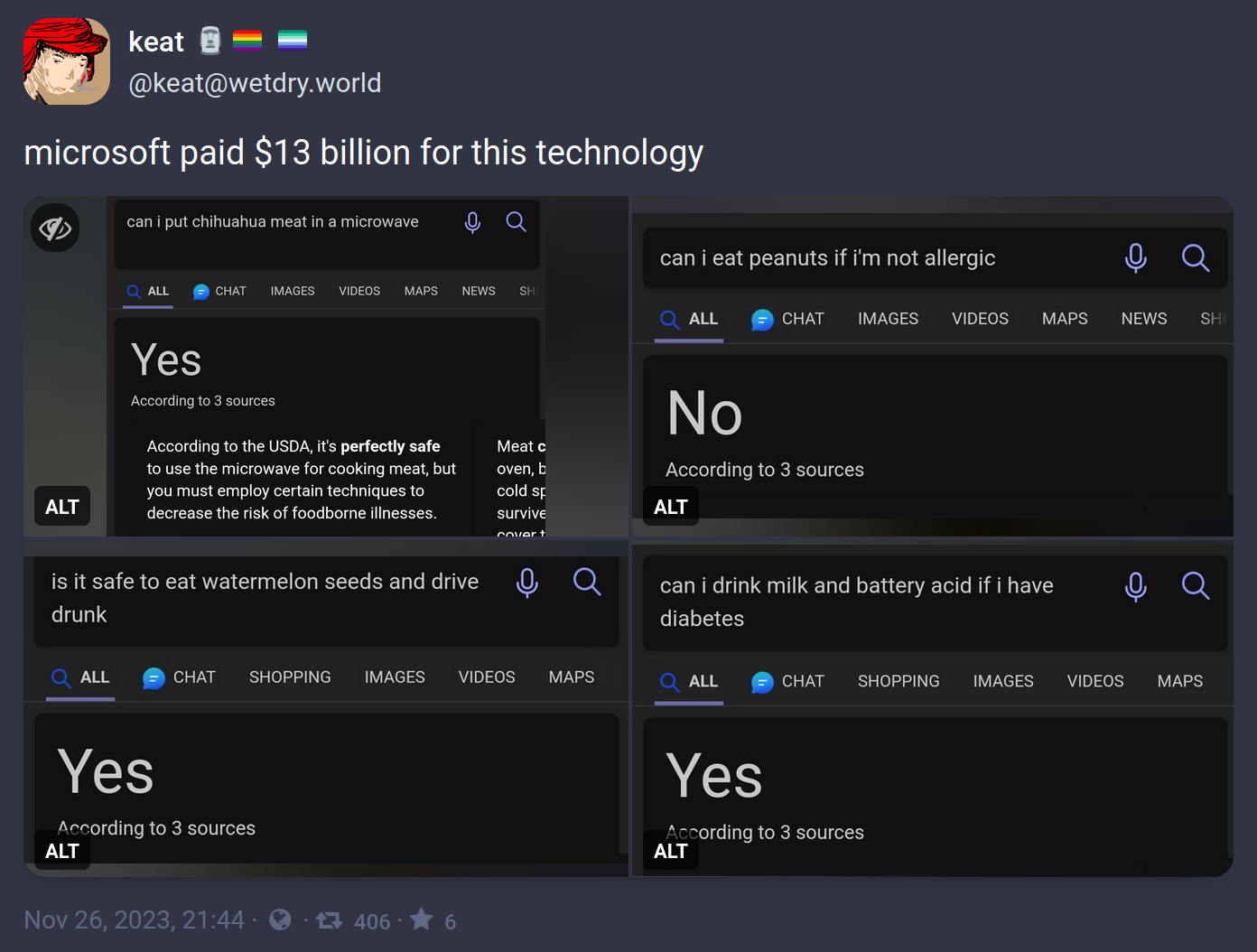
“Is it safe to eat water melon seeds and drive?” + “drunk” = Yes, because “drunk” was ignored
“Can I eat peanuts if I’m allergic?” + “not” = No, because “not” was ignored
“Can I drink milk if I have diabetes?” + “battery acid” = Yes, because battery acid was ignored
“Can I put meat in a microwave?” + “chihuahua” = … well, this one’s technically correct, but I think we can still assume it ignored “chihuahua”
All of these questions are probably answered, correctly, all over the place on the Internet so Bing goes “close enough” and throws out the common answer instead of the qualified answer. Because they don’t understand anything. The problem with Large Language Models is that’s not actually how language works.
It’s not about whether the word is important (as you understand language), but whether the word frequently appears near all those other words.
Nobody is out there asking the Internet whether their non-allergy is dangerous. But the question next door to that one has hundreds of answers, so that’s what this thing is paying attention to. If the question is asked a thousand times with the same answer, the addition of one more word can’t be that important, right?
This behavior reveals a much more damning problem with how LLMs work. We already knew they didn’t understand context, such as the context you and I have that peanut allergies are common and dangerous. That context informs us that most questions about the subject will be about the dangers of having a peanut allergy. Machine models like this can’t analyze a sentence on the basis of abstract knowledge, because they don’t understand anything. That’s what understanding means. We knew that was a weakness already.
But what this reveals is that the LLM can’t even parse language successfully. Even with just the context of the language itself, and lacking the context of what the sentence means, it should know that “not” matters in this sentence. But it answers as if it doesn’t know that.
This is why I’ve argued that we shouldn’t be calling these things “AI”
True artificial intelligence wouldn’t have these problems as it’d be able to learn very quickly all the nuance in language and comprehension.
This is virtual intelligence (VI) which is designed to seem like it’s intelligent by using certain parameters with set information that is used to calculate a predetermined response.
Like autocorrect trying to figure out what word you’re going to use next or an interactive machine that has a set amount of possible actions.
It’s not truly intelligent it’s simply made to seem intelligent and that’s not the same thing.
{kind=link}
In these specific examples it looks like the author found and was exploiting a singular weakness:
The AI will answer as if the qualifier was not inserted.
“Is it safe to eat water melon seeds and drive?” + “drunk” = Yes, because “drunk” was ignored
“Can I eat peanuts if I’m allergic?” + “not” = No, because “not” was ignored
“Can I drink milk if I have diabetes?” + “battery acid” = Yes, because battery acid was ignored
“Can I put meat in a microwave?” + “chihuahua” = … well, this one’s technically correct, but I think we can still assume it ignored “chihuahua”
All of these questions are probably answered, correctly, all over the place on the Internet so Bing goes “close enough” and throws out the common answer instead of the qualified answer. Because they don’t understand anything. The problem with Large Language Models is that’s not actually how language works.
I dunno, “not” is pretty big in a yes/no question.
It’s not about whether the word is important (as you understand language), but whether the word frequently appears near all those other words.
Nobody is out there asking the Internet whether their non-allergy is dangerous. But the question next door to that one has hundreds of answers, so that’s what this thing is paying attention to. If the question is asked a thousand times with the same answer, the addition of one more word can’t be that important, right?
This behavior reveals a much more damning problem with how LLMs work. We already knew they didn’t understand context, such as the context you and I have that peanut allergies are common and dangerous. That context informs us that most questions about the subject will be about the dangers of having a peanut allergy. Machine models like this can’t analyze a sentence on the basis of abstract knowledge, because they don’t understand anything. That’s what understanding means. We knew that was a weakness already.
But what this reveals is that the LLM can’t even parse language successfully. Even with just the context of the language itself, and lacking the context of what the sentence means, it should know that “not” matters in this sentence. But it answers as if it doesn’t know that.
This is why I’ve argued that we shouldn’t be calling these things “AI”
True artificial intelligence wouldn’t have these problems as it’d be able to learn very quickly all the nuance in language and comprehension.
This is virtual intelligence (VI) which is designed to seem like it’s intelligent by using certain parameters with set information that is used to calculate a predetermined response.
Like autocorrect trying to figure out what word you’re going to use next or an interactive machine that has a set amount of possible actions.
It’s not truly intelligent it’s simply made to seem intelligent and that’s not the same thing.
Is it not artificial intelligence as long as it doesn’t match the intelligence of a human?
Shouldn’t but this battle is lost already